アメリカでCS博士課程に合格するための戦略について考える
はじめに
この記事で書かれている内容は2022年2月現在の内容であり、筆者の個人的な見解を多分に含みます。 出願までのプロセスについては、日本の学部からアメリカのコンピューターサイエンス博士課程に出願する - あさりさんの作業ログや船井財団の奨学生の方々の報告書に詳細がまとまっており非常に参考になると思います。
自己紹介
2018年に東京工業大学電気電子工学科を卒業し、大学院進学時の転学科を経て情報理工学院の修士課程を修了しました。 修士課程の最終年度に米国大学院博士課程を受験するも全滅し、CMU Robotics Instituteの修士課程(Master's in Robotics)のみに運良く合格し進学しました。 その後、同学科のPh.D.プログラムから正式にオファーをいただき、2022年9月よりCMU Robotics Insituteの博士課程に進学予定です。
アメリカにおける出願事情
近年、アメリカCS博士課程は人工知能ブームが相まり競争が非常に激化しています。 例えば、CMU Robotics InstituteのPhDプログラムでは800人程度の出願に対して合格人数は35人程度(合格率約4%)と非常に狭き門となってるようです。 そのため、中国やインドを始めとする世界中の優秀な学生に対して出願パッケージを差別化し、アピールしていくことが重要になってきます。
合格するための戦略について考える
日本の大学から米国のCS博士課程に出願する際の基本的な戦略としては、以下の3つが主に考えられます。
- 学部の早い時期(学部2年ごろ?)から研究に取り組みトップ会議のワークショップや2ndや3rd Tierの会議への採択を目指す(トップ会議の論文があったらベスト)。その後、学部から直接出願する。この場合は研究実績よりもポテンシャルをより重視される場合が多いです。論文が出願時点で採択されていなくても、一定の研究経験があれば合格を得られる可能性があります。
- 修士まで日本の大学で研究に取り組み、トップ会議への論文の採択を目指す。この方法だと、志望大学の教員との研究経験やコネクションなどがない限り、基本的に最低一本はトップ会議に論文が採択されていないと合格はかなり難しいです。
- 米国大学院の修士課程に進学し、研究実績を積みながらトップ会議での論文採択を目指す。修士卒後で論文がない場合でも修士課程なら合格をもらえる可能性が高いです。授業と並行しながら研究を行うのは非常に大変ですがやりがいは大きいです。コースワークベースのプログラムではなく、CMUやGeorgia Techなど一部の大学が提供する研究ベースのプログラムなどでは財政的支援を得られる場合もあります。
正直言って、どの方法も簡単ではありません。僕の場合は決断が遅く、2および3の選択しか残されていませんでした。結果的に最後の頼みの綱である3でなんとかなりましたが、1および2の戦略をまずは検討されることをおすすめします。 次に、出願パッケージのそれぞれの項目の重要度について(主観的ではありますが)少し解説したいと思います。
研究経験・実績
なにがともあれ、研究経験がなければ博士課程に合格することはできません。 これは必ずしも論文が必要ということを意味しないのですが、周りを見ている限りトップ会議の筆頭論文が少なくとも1本ないとCSトップ校への合格は難しいと思います。 日本では学部時代から研究室に所属することは一般的ではありませんが、直接教授などに連絡を取るなどすれば受け入れてくれる場合もあると思います。 早い段階で研究に取り組み始めることで、出願までに一定の研究経験・実績を積むことができるはずです。
推薦状
推薦状は唯一の客観的な資料になります。そのため、選考過程において研究実績と同程度(かそれ以上)に重要視される場合が多いです。 基本的には3通の推薦状が必要になり、2通以上は教授から書いてもらえることが望ましいです。 応募者自身がコントロールできないところではありますが、普段から自発的に研究をすることで良い推薦状を書いてもらいましょう。 逆に言えば、少しでも悪い推薦状を書かれそうな場合は、他の人に頼むなどの戦略も重要です。 僕は、1) CMUの修士課程での指導教員, 2) 共同研究プロジェクトのPI, 3) 東工大の修士課程での指導教員に書いていただきました。
Statement of Purpose (SoP)
大事だと思いますが、上記2つほどではないです。文法や単語などのミスはご法度なので、添削は何度もしましょう。 参考までに僕は下記のような流れで書きました。
- イントロ: PhDを通して目指したい将来像など
- 研究経験: 2段落に分けて今までの研究経験など
- 応募理由: 志望大学・教員を選んだ理由など
TOEFL
TOEFLに関しては100点を超えれば基本的に十分です。すべてのセクションで少なくとも20点は超えていた方が良いと思います。 勉強方法に関しては人それぞれかと思いますが、受ける前に目標点数を決めるのではなく一旦受けてみて自分の実力を知るのが大事です。 僕は初めて大学2年時にTOEFLを受けたときに70点代後半で絶望した記憶があります。 その後、研究室で英語をしゃべるように意識したり、インプットをなるべく英語に統一するなど意識することで最終的には106点まで伸びましたがスコアメイクにはかなり苦労しました。
GRE
GREを受け付けない大学も多くなっているので、まずは志望大学がスコアを必要としているか調べましょう。 点数に関してはQがそこそこ取れていて出願パッケージの他の項目が魅力的であれば、あまり気にされないと思います。 僕のスコアはV:145, Q:169, W: 3.5というお世辞にも良いとは言えないスコアでしたが問題ありませんでした。 GREを勉強する時間があったら、研究に時間を充てるほうがいいと思います。
奨学金
日本以外からの留学生を見ている限り、奨学金は合格には必須ではないように思います。ただ、一定の倍率を突破して奨学金に採択されていることはそれだけで一定の能力の証明になりますし、教員の財政的負担を減らすことができるので、応募資格がある場合は必ず応募しましょう。学校推薦が必要な奨学金は応募期日が早いことが多いので、早めに情報を確認されることをおすすめします。
事前コンタクト
事前コンタクトは重要ではあると思いますが、基本的には何も実績がない状態でメールを送ってもほとんど返ってきません。 それでも、少しでも可能性を上げるために必ず志望教員にコンタクトは取ったほうがいいと思います。 今までの研究の実績、志望研究室でやりたい研究について簡潔に書いて "Inquiry about potential PhD opportunities from Fall 20xx" のようなタイトルでメールを送るといいでしょう。
これからアメリカでCS博士課程を目指す方へ
博士課程合格への道のりは不安定なだけでなく、とてもストレスがかかります。僕は結果が出るまで毎日GradCafe(受験結果を投稿できる掲示板)を見ながらやきもきしていました。 もし受験に関して不安であったり、質問があればsiwase@cs.cmu.edu宛にメールをいただければ時間のあるときに答えられると思います。気軽に連絡してください。
by Shun
カーネギーメロン大学での1年目を振り返る
カーネギーメロン大学(以下CMU) Robotics Insituteにて修士学生として留学を始めてから約1年が経った。 パンデミックの最中で、授業・研究が全てオンラインになったりと中々荒々しいスタートだったけど、人生において最も大きな学びのあった1年だった。 この記事では、記憶が新鮮なうちに授業・研究に関してこの1年間の個人的な感想をまとめたいと思う。 ついでに、米国大学院留学(特にコンピュータサイエンス)を検討している方向けに、僕の所属するプログラムについても簡単に説明したい。

所属するプログラムについて
僕は現在、Master of Science in Robotics (以下MSR)という2年間の修士課程に所属している。 米国では一般的に修士プログラムではコースワークのみしか提供しない場合が多いが、MSRは研究(修論発表)とコースワークの両方を要件とするプログラムになっている。 立て付けとしては日本の一般的な修士過程に近い。そのため、僕のいる学科では博士課程で直接学生を多く取るということはせず、修士課程修了後に博士課程に内部進学するということが一般的になっている。 これは、米国の研究ベースの大学院プログラムでは修士課程を設けていない場合が多いという点でユニークだと思う。
修士課程から博士課程に内部進学する際には、内部での競争*1を勝ち抜く必要がある。 ただ実際は、博士課程への進学希望者は内部進学ができなかった場合でもトップ大学の博士課程に進学できている場合が多い。他にも、卒業後に企業に直接就職するという学生も一定数(正確な数字は分からないが20~30%くらい)いる。 米国での博士課程は5~7年程度の期間がかかるのが一般的ではあるが、学部卒業後にこの決断をするのはやはり少し難易度が高い。 2年間の研究ベースの修士過程を最初に経験することは、自身が研究にどれくらい興味や適性があるかを知るための良い試金石となるので、個人的には米国にもっとこういった研究ベースの修士プログラムが増えると嬉しいと思っている。
次に、多くの方が気になるであろう、修士課程での費用について少し説明したい。一般的に、米国の修士課程はコースワークのみを前提としている場合が多いため、授業料および生活費を基本的には自腹で払う必要がある。 CMUは米国でも授業料がダントツで高いことで有名で、年間5万ドル(約600万円)程度の費用がかかる。これに生活費を含めると年間8~9万ドル(約900~1000万円)になる。 しかし、MSRは研究ベースの修士プログラムということもあり、企業や他の研究機関との共同研究によるファンディングを通して、授業料のサポートを受けている学生が多い(指導教員によっては生活費のサポートがある場合もある)。 僕の場合は、幸いにも指導教官および吉田育英会から授業料および生活費(約$3,000, 33万円/月)の支援をいただくことができている。 日本にいた頃は授業料や生活費を自分で払っていたこともあり、仕事と研究の兼ね合いが非常に難しかった。その点で、留学後の1年間は非常に恵まれた環境で研究に取り組むことができたように思う。

授業
この1年で4つの授業を受講した。 日本の感覚からすると非常に少ないように感じるかもしれない。しかし、全ての授業が週5~10h程度かかる課題を2週間ごとに課すというスタイルだったので、日本の大学院で倍の数の授業を受けるのと同等程度の負担だった。 研究と並行して授業をこなすのは大変だったけれども、クラスを通して出来た友人と一緒に悩みながら(時に文句を言いながら)課題に取り組めたので気持ち的には非常に楽しめた。 肝心の授業に関しては、流石のCMUクオリティであり、どれも素晴らしいものが多かった。特に課題に関してはかなりよく練られており、研究の基礎力をつけるという意味で非常に役立つものが多かった。 また、教員および学生の授業に対するモチベーションも高く、授業中の質問やディスカッションを通して、授業内容に関してより深い理解を得ることができたように思う。 他にも最新のトピックをしっかりと扱っていたのも良かった。日本の大学院にいた際はスライドの更新が5~6年前で止まっているという授業も多くあったので、もう少し母校には頑張って欲しいな...とも思う。 それぞれの授業の簡単な感想はこんな感じ。
16-720 Computer Vision (Fall 2020)
古典的なコンピュータビジョンのアルゴリズムから深層学習まで幅広いトピックについて扱ったコンピュータービジョンの応用クラス。控えめに言っても本当に最高の授業だった。 アルゴリズムの歴史的経緯や理論的背景だったりを授業では説明しつつ、課題ではそれぞれのアルゴリズムをPythonで実装するということをやった。 コンピュータビジョンにおいて良く用いられる、DLTアルゴリズムを用いたホモグラフィ行列の推定、PnPアルゴリズムを用いた姿勢推定、ハフ変換、SIFTアルゴリズムだったりを自分で実装するというのは非常に楽しかった。 並行して行っていた研究でも非常に役に立ったので、授業を侮ってはいけないなという気持ちを強く感じた。同時に、こういった授業がCMUの高い研究力の源泉になっているんだろうなと思ったりもした。
16-811 A Math Fundamentals for Robotics (Fall 2020)
ロボティクスにおいて多用される線形代数や微分幾何学の基礎を扱ったクラス。必修かつ多くの学生が最初のセメスターで受講すると聞いたので選択した。 線形代数や微分幾何学については学部の時に学んだけれども色々忘れていたし、ロボティクスおいてどのように用いられているかについてもほとんど知らなかったのでためになる授業だった。 内容は少し基礎的だったけれども、英語の授業や課題に慣れるという意味では逆に良かったのかもしれない。
16-824 Visual Learning and Recognition (Spring 2021)
古典的な学習ベースの画像認識アルゴリズムについて扱ったクラス。 人間がどのように視覚情報を知覚するのかという哲学的な話から始まり、古典的なFew-shot, Zero-shot 物体検出アルゴリズム、最新の深層学習を用いた画像認識 (VGG16, ResNet, Transformerなど), 深層強化学習と目まぐるしくトピックが変化していきローラーコースターに乗っているような気持ちだった。 授業にあまり一貫性がなかったのと結構知っていることが多かったので、少し退屈だと感じる時もあったけど全体としてはいい授業だったと思う。
16-711 Kinematics, Dynamics and Control (Spring 2021)
剛体変換、スクリュー理論、順運動学、逆運動学, PID制御などを通したマニピュレータの操作方法を扱ったクラス。 最初の剛体変換までは簡単だなと思っていたけど、スクリュー理論の授業から突然授業の速度が上がり全くついていけなくなっていて焦った。その後、実は誰もついていけてないことを知り安心したのも束の間、授業はそのままのスピードで進んでいった... ただ、課題が非常によくできていたので、授業で理解ができなかった箇所も課題を通して理解を深められるようになっており、最終的には授業で扱った全てのトピックについて深い理解を得ることができたように感じた。 デバッグに苦しみながら最後の課題を終えた時にマニピュレータの軌道が授業名(KDC)になっていて、月並みだけどこういう遊び心があるのがいいなと思った。

研究
研究ベースの修士プログラムなので、週一で指導教員とミーティングをしながらポスドクの学生と一緒に3次元物体検出に関する研究を行なった。 最初の方はミーティングが英語ということもあり緊張していたけど、3ヶ月くらいしたら慣れた気がする。 ミーティングは、基本的には研究の進捗報告を行った後に、研究における気付き、課題に関して議論を進めるという方針で行っていた。 毎回良質なフィードバックを得ることができたおかげで、この1年は授業と並行していたのにも関わらず良いペースで研究を進めることができた。 指導教員、ポスドクおよび研究室の学生が協力的かつモチベーションが高いということもあり、心理的な安全性が保たれた状態で適度な緊張感を持って研究に取り組めたことも良かった。 さらには、さまざまな分野のエキスパートが揃っていたことも、研究における試行錯誤の回数を増やすことに大きく貢献していたように感じる。この記事にもあるようにやはり成功回数は試行回数に大きく左右されるように思う。 その意味で、彼らの存在が僕の取り組んでいた研究を加速させてくれたというのは疑いようがない。 最終的に、この1年間の研究成果として主著がコンピュータビジョン系のトップ会議であるICCVに採択され、第二著者として、IROSとICCVにそれぞれ論文が1本ずつ採択されるという考え得る最高の結果を得ることができた。

まとめ
去年までは長期留学もしたことがなかったし、トップ会議などに論文もなく、受験の際もアメリカの博士課程に出願するも全滅していたので、CMUの修士課程終了後にもトップ大学の博士課程に受からないんじゃないかという不安があった*2。 けれども、今年はなんとか全ての授業でAまたはA+を取ることができ、アカデミアにおける初めての成功体験も得ることができた。今年の受験ではどこかしらの博士課程に受かると良いなあ...理想をいえばこのままCMUの博士課程に進学したい*3。とはいえ、博士課程に合格することが目的のつもりはないので、さらにどんどん加速して成長して目標に近づいていきたい。 また時間がある時に、今住んでいるピッツバーグについてだったり、もう少しプライベートなことについても書こうと思います!
From Shun
Batch Normalizationについてのメモ
概要
Batch Normalizationとは,2015年にGoogleの社員2人が提案したパラメータの最適化手法の1つである.
問題
ニューラルネットワークを用いて学習をする際,データに何かしらの前処理を施すことが一般的である.これは,以下の理由などで行うことが多い:
- sigmoid関数などで引き起こされる,早い段階での勾配消失を無くす
- 全てのデータが一定の範囲内に収まるようにする
- etc.
しかし,問題は前処理だけで解決されない. 入力データの分布と推定データの分布が異なる現象をCovariate Shiftという. 例えば,学習データとして黒猫のみを用いると,黒い猫を判定できるモデルが生成される.そこに,三毛猫を判定させようとすると,うまくいかない,という原理である.
そして,同じような現象が,層が深いネットワーク内でも発生する.これをInternal Covariate Shift という.これは,層の入力データの分布と出力データの分布が違うことで発生する.各層は,データの分布に適応しようと学習を行う.しかし,層が深くなるにつれ,データの分布は初期状態から違うものになってしまう.これは,イテレーションが増す毎に酷くなる.
そこで,全てのレイヤーにおいて,データがほぼ同じ分布になるように強制的に変えてしまう,というのがBatch Normalizationである.
解決手法
上記のInternal covariate shiftを無くすための手法としてBatch Normalizationが提案された. 学習中,以下の手法によって,正規化を行う:
- レイヤーの入力値の平均と分散を計算
- 1の値を用いてレイヤーの入力値の正規化を行う
- レイヤーの出力値を得るために,シフトを行う

既存の層に対して,2つのパラメタのみ追加することでBatch Normalizationは実装ができる.
利点
- 学習が早く進む
- learning rateを比較的大きく設定ができる
- Batch Normalizationによって,活性化されても大きすぎたり,小さすぎる出力が得られないようになる
- 過学習を防ぐ
- Dropoutと似ており,隠れ層にノイズを含めることができる
- Dropout回数を減らすことができる
考察
BNはネットワーク内部の活性化の正規化をすることによって,結果に大きな違いを生み出すことができるようになった.
参照
vimのカラースキームの設定・編集方法(初心者〜上級者)
背景
このあいだ勉強会の一環で vim・Neovimのカラースキームについて 紹介したので,それをこちらでも記事として残そうと思います. 自分はカラースキームを探したり,環境にあった色にチューニングしたりが好きです.そこで,そういったことをしている中で培って来た知識を「カラースキームってなに?」という人から,「カラースキームを編集したい」という人まで,広く浅く紹介したいと思います.
他にもcocoponさんの記事なども非常に勉強になると思います.
前提条件
vimの環境によっては異なるカラースキームや設定方法がある可能性があります. 今回はvimとNeovimを使用した場合の2種類で紹介しますが,もし他の設定方法がある場合にはコメント等よろしくお願いいたします)
Neovim: NVIM v0.3.4
勉強会の際に作成したスライド:
はじめに
カラースキームに凝ること,2年.vimの戦闘力はvimrcの行数という説があります. ある意味面白い例えだと思ったので,自分もカラースキームの戦闘力的何かがあれば面白いと思い考えました.
その結果,

というレベル分けで紹介することにしました (他の分け方もあるかと思いますが笑) 今回も,この5段階と分けて紹介をしようと思います!
カラースキームとは
カラースキームとは,簡単に紹介すると
vimの色の付け方を指定するもの
です. しかし,カラースキーム好きとしてさらに踏み込むと,
vimを開きたくなるもの
ですね.
下の図を見ていただくとわかると思いますが,カラースキームの有無で大きく「見やすや・かっこよさ」が異なることがわかると思います.

では,実際にカラースキームの設定や編集方法に移りたいと思います.
設定方法
Level 1 - デフォルトのカラースキームを使用
デフォルトってなんだ? と思われる方もいらっしゃるかと思います. 実は,vimはインストールした時点でいくつかのカラースキームが一緒にインストールされます.
自分のmacのvimの場合,下記の18種類が入ってました!(ほとんど使ったことがない...)
(/usr/share/vim/vim80/colors内に存在しました.)
blue.vim darkblue.vim default.vim delek.vim desert.vim elflord.vim evening.vim industry.vim koehler.vim morning.vim murphy.vim pablo.vim peachpuff.vim ron.vim shine.vim slate.vim torte.vim zellner.vim
レベル1ではこの辺を設定するところから始めたいと思います.
一時的に反映
:colorscheme コマンドについて
カラースキームの設定方法の前に,いくつか便利なコマンドを紹介したいと思います.
まず,vimの画面上でどんな感じになるか確認したいと思われる方もいらっしゃるかと思います. vimはそれができます!
vimの画面上で
:colorscheme[space][tab]
と打つとコマンドライン上にpc内に入っているカラースキームのリストが表示されます.

この状態で, 矢印キーで左右に動き,見たいカラースキームの上で Enterを押すと,そのカラースキームが反映されます.
しかし,これは一時的な反映 であり,再度vimを開くと,元のカラースキームに戻ってしまいます.
全体に反映
全体に反映するには .vimrc 内に記述します.
.vimrc とは
.vimrcとは:
vimの設定を記述する専用ファイル
です.簡単な設定から,パッケージについて等,全てこのファイルに記述します.(正確には他のファイルでも良いのですが,このファイルに最後に source をしないと,反映されません)
ちなみに豆知識で, .~rc 系の設定ファイルをよく見かけるので,rcってなんなんだろうと調べたところ,初期のUNIXの遺産のようで run commands の略ではないかという説があるらしいです.
.vimrc どこにあるんだ
自分が初めてvimを触りだしたところ, .vimrcを見つけられず,苦労をしました.(サイトによって,記述場所が異なっていたり,Neovimだったので,vimとは違って大変でした...)
そこで,簡単に今のvimがどの設定ファイルを読み込んでいるのか見つけられるコマンドがあります.
それがこちら!
:echo $MYVIMRC
こうすることによって,
$ HOME/.vim/.vimrc or $ HOME/.config/nvim/inti.vim
となります.上記がvimの場合で下記がnvimの場合です.
※ neovimの.vimrcはinit.vimというファイルです
あとは.vimrcに記述するだけ!
.vimrc の場所がわかれば,あとはそこに記述するだけです.
書き方は非常にシンプルで
syntax enable colorscheme [colorscheme name]
とするだけです.
Level 2 - 公開されたカラースキームを使用
公開されたカラースキームとは
GithubやBitbucketなどのOP上で公開されたカラースキームのこと
と定義しました. 多くの人がこういった,公開されたカラースキームを使用するのではないかと思います.
使用方法として2種類あります. 1. 自分のpc上にダウンロードして使用 2. パッケージを使用してインポートして使用
よく見かける王道のカラースキームは下記のようなものがあげられると思います.

では,実際にmolokaiを例に設定する方法を紹介したいと思います.
1. 自分のpc上にダウンロードして使用
デフォルトのカラースキームはcolors/というディレクトリ内に存在しました.
そこと同じディレクトリに入れる方法もありますが,一般的には下記のようなディレクトリ構造を作成し,その中に入れます.
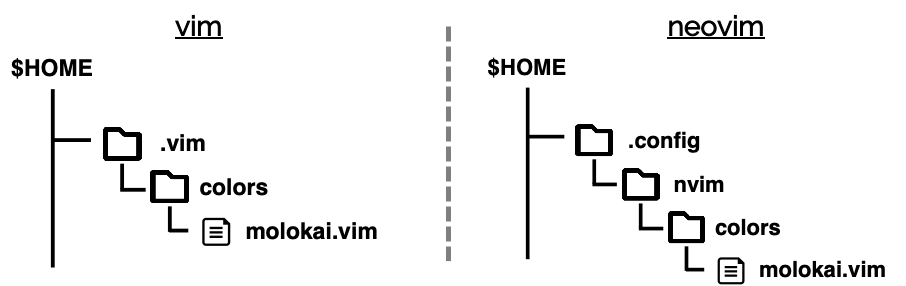
注意: 初期状態では存在しない場合,mkdir等で作成してください.
あとは,そこにmolokaiのカラースキームファイルをダウンロードするだけです.
githubからcloneして,./colors/molokai.vimというファイルを先ほど作成した./colors内に移動するだけです.
あとは上記のデフォルトのカラースキームを使用した時と同様のことを.vimrc内に記述するだけです.
syntax enable colorscheme molokai
2. パッケージを使用してインポートして使用
「自分のpc上にダウンロードして使用」でも良いのですが,新しいカラースキームを取り込みたい時に,いちいちダウンロードして,移動して,と行なっているのは面倒臭いです.
そこでdeinというパッケージを使用して簡単に取り込む方法を紹介したいと思います.
そちらのインストール方法などは,また別の話になるので割愛させていただきますが,以下の記事がインストール方法などを紹介しているので是非,使っていない人は試してみてください!
(オススメのパッケージに関するスライドはこちら)
実はこのdeinを使用すると2行だけで終わってしまいます.
ディレクトリを作成する必要もないです.
call dein#add('tomasr/molokai')
colorscheme molokai
これで全体に反映されてしまいます.
以上がレベル2の紹介です!
では,実際に編集の方に入っていきます.
編集方法
カラースキームを追求していくうちに,編集したくなる欲求が出てくきます(来ない人ももちろんいます)
そこで,実際どう編集するのか,そしてそのための便利ツールを紹介したいと思います.
事前知識
ターミナルについて
vimを使用していると,2種類のterminalに出会います.
1つ目がcterm,そして2つ目がGUIです. これらの大きな違いは色の数です.
ctermは256色しか色がないターミナルです.macのデフォルトはこちらになります. また,色のパレットはXterm colorsというのを使用しています.
GUIは名前の通り,グラフィックに適応しているのでhexで色分けがされています.
基本的に,公開されているカラースキームはどちらのターミナルにも対応しているので,中身を見ると
hi Operator guifg=#af0000 guibg=NONE guisp=NONE gui=bold ctermfg=124 ctermbg=NONE cterm=bold
のように,書かれています.それは以下のような意味があります.

ctermのターミナルの色を変える場合, ctermbg / ctermfg を変更し, GUIのターミナルの色を変えたい場合は guibg / guifg を変更します.
ハイライトグループについて
カラースキームはハイライトグループごとに色が振り分けられています.これらのシンタックスグループは言語をvimに登録する際に決められており,例えば下記のようなものがあります.

なので,一概に「この色を変えたい!」と言っても,他の要素が影響を受ける場合もあるので十分に注意してから変えたほうがいいです.
ANSIIの設定

レベル3: 公開されたカラースキームをカスタマイズして使用
では,これらの知識をもとに色を編集する方法を紹介します.
便利コマンド・ツール
その前に,編集を行う際の便利コマンド・ツールについてです.
現在のカラースキームをグループごとの色を知る方法
今のカラースキームが全体的にどのような色分けになっているのか知る方法として以下のコマンドがあります.
:highlight もしくは省略して :hi
とvimのコマンドライン上で打つと下記のような画面が表示されます.
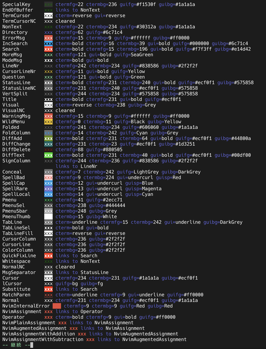
これらは右から
ハイライトグループ 表示例 色
です.
Xterm Color Table
いちいちXtermの色を調べるのは面倒臭い上に,現在のターミナルでどのような色になるのか知りたい場合,こちらのプラグインが役に立ちます.
gitのREADME.mdにも記述されているのですが,このプラグインを.vimrcに記述するだけで, :XtermColorTableというコマンドが使用できるようになります.
実際,下記のようになります.
https://github.com/guns/xterm-color-table.vimのREADME.mdから引用
シンタックのグループ名を知れる関数
色を帰る際に非常に困るのが,変えたいところのハイライトグループがわからない!ということです. そこで,cohama様のこちらの記事に書かれている関数が非常に便利だったので紹介したいと思います.
function! s:get_syn_id(transparent)
let synid = synID(line("."), col("."), 1)
if a:transparent
return synIDtrans(synid)
else
return synid
endif
endfunction
function! s:get_syn_attr(synid)
let name = synIDattr(a:synid, "name")
let ctermfg = synIDattr(a:synid, "fg", "cterm")
let ctermbg = synIDattr(a:synid, "bg", "cterm")
let guifg = synIDattr(a:synid, "fg", "gui")
let guibg = synIDattr(a:synid, "bg", "gui")
return {
\ "name": name,
\ "ctermfg": ctermfg,
\ "ctermbg": ctermbg,
\ "guifg": guifg,
\ "guibg": guibg}
endfunction
function! s:get_syn_info()
let baseSyn = s:get_syn_attr(s:get_syn_id(0))
echo "name: " . baseSyn.name .
\ " ctermfg: " . baseSyn.ctermfg .
\ " ctermbg: " . baseSyn.ctermbg .
\ " guifg: " . baseSyn.guifg .
\ " guibg: " . baseSyn.guibg
let linkedSyn = s:get_syn_attr(s:get_syn_id(1))
echo "link to"
echo "name: " . linkedSyn.name .
\ " ctermfg: " . linkedSyn.ctermfg .
\ " ctermbg: " . linkedSyn.ctermbg .
\ " guifg: " . linkedSyn.guifg .
\ " guibg: " . linkedSyn.guibg
endfunction
command! SyntaxInfo call s:get_syn_info()
これを.vimrc内に記述すると,:SyntaxInfoというコマンドが使用可能になり,実際にカーソルの下にあるコードのハイライトグループがわかります!link toのリンク先まで知れるのはありがたいです.
表示例:

以上,編集においての便利コマンド・ツールとなります.
一時的に編集をしてみる
実際に全体に反映させる前に,どのようになるのか一時的に編集させる方法があります.
それが先ほども紹介したhighlight / hiコマンドです.
例えば,行番号の背景色を変えたいとした時,赤がどのような感じになるか確認します.
この時,赤をhexの#ff0000とした時,xterm256では1に該当します 1 .
:highlight LineNr ctermbg=1 guibg=#ff0000 もしくは :hi LineNr ctermbg=1 guibg=#ff0000
ここで行なった編集は,現在のvimの画面にしか反映がされません.
なので,気に入ったものは.vimrcやカラースキームをダウンロードして直接編集しましょう.
全体に反映
.vimrcに記述する方法
感覚で,もし色を変えるのなら,下記のようにカラースキームを設定した後に変えたい箇所の色を上書きすればいいのでは?と思われるかもしれません.
colorscheme foo-bar highlight LineNr ctermbg=1 guibg=#ff0000
しかし,上記には穴があり,正しい書き方があるらしいです.
その理由を説明しているのがこちらです. 英語+長いので要点だけ取り出すと,以下のことが問題となります.
But you like to try new colorschemes, or you prefer to have different colorschemes for different filetypes or time of the day and your overrides don't carry over when you change your colorscheme.
なので,カラースキームをインポートする前に下記のように記述しましょう.
autocmd ColorScheme * highlight LineNr ctermbg=1 guibg=#ff0000 colorscheme foo-bar
直接カラースキームファイルに記述する場合
この場合はカラースキームファイルをクローンしてきて,変えたいところを探し,置き換えるだけです.
ただ,この場合,もしgitに載せたりする場合は著作権などに気をつけるべきですね.
以上でレベル3の編集については終わりです.
レベル4: 自作カラースキームを使用
ここまできたら,実際に作ってみようと思われた方もいらっしゃるかと思います. しかし,実際に作るとなると,色々大変なことが多いです.
thincaさんの記事やcocoponさんのIcebergを作成した際の記事が自作する際に読んでおきたい記事です!
私はデザイナではないので,デザインに関することは言えないのですが,その代わり作成する際に非常に役に立ったおすすめサイト・ツールなどを紹介したいと思います.
手順
下記は,いろんな人のカラースキームを拝見した際に行なっていると思われる手順です.

オンライン編集ツール
Vivifyというこちらの編集ツールが非常に役に立ちます.
テストコード
Rosetta Code Dataのこちらのレポジトリには数多くの言語で書かれたコードがあります.
.vimrcに記述
~/.vim/colorsもしくは~/.config/nvim/colors内にファイルを置くと,.vimrcで設定することができます.
書き方は上記のデフォルトや公開されたカラースキームと同様です.
レベル5: 自作カラースキームを公開し使用する方法
あまり,レベル4と差異はないのですが,公開するというところが重要だと思い別のレベルにしました.
Githubに公開する方法は非常に単純で,ディレクトリ構造などを間違えなければすぐできます.

パッケージ等で読み込むのは./colors内のトップのファイルのみなので,そこだけ注意が必要そうですね.
最後に
本当に広く浅くで紹介しました. もし間違っている箇所などございましたら,コメントよろしくお願いいたします.
参照サイト
How to set and use a vim color scheme: https://alvinalexander.com/linux/vi-vim-editor-color-scheme-colorscheme molokaiのカラースキーム: https://github.com/tomasr/molokai Vim のカラースキームが微妙に気に食わないときの対処法: http://cohama.hateblo.jp/entry/2013/08/11/020849
-
terminalによっては,ANSIIのパレットの色によって少し異なる色が出力される可能性があります.
:XtermColorTableなどでxterm256の色合いを調べつつ,もっとも求めているものに近い色を探してください.↩
Pybind11をパッケージ化するまでの流れ

背景
Pythonのfor文は計算時間が長いという問題があり、そこを高速化したかったので、C++でアルゴリズムを書いて、pythonにインポートするということをしました。
その際、pybind11というパッケージを利用したのですが、まだあまり参考にできる記事が少なかったので、その際のメモを残したいと思います。
環境
OS: macOS Mojave 10.14.2 python: pyenv 3.6.5
Pybind11とは
公式github: https://github.com/pybind/pybind11 公式ドキュメント: https://pybind11.readthedocs.io/en/stable/
pybind11とは公式ドキュメントによると
pybind11 is a lightweight header-only library that exposes C++ types in Python and vice versa, mainly to create Python bindings of existing C++ code.
ということです。つまり、PythonにC++のコードを、またC++にPythonのコードを繋げることができるライブラリです。
実はこういったことを行ってくれる他の1つのライブラリもあり、その1つにBoost.Pythonというのがあるらしいです。が、自分は触ったことがないので、こちらの参考サイトのみ載せておきます。
Pybind11とBoostの大きな違いはBoostはとても大きいライブラリだということです。単純なモジュールを呼ぶためだけにBoostを使うのは非効率的ということもあり、Pybind11は作成されました。
その辺の詳しいベンチマークなどはこちらに詳しく書いてあるので、興味あればみてみてください!
インストール方法
インストール方法は何通りかあるのですが、今回自分はpipを使ったのでそちらの方の紹介をします。
$ pip3 install pybind11
この他にもgithubからのインストール方法もあるのですが、実行方法が異なってくる(コンパイルする際のコマンドが違うため)ので、気をつけた方がいいです!
実装例(簡易版)
背景にも書いたのですが、自分はpythonのfor文の計算量が多いのが問題となっていたので、配列を用いたモジュールを書きました。が、公式にも英語のサイトにも中々配列の使い方が綴られておらず(自分の裁量不足ということもあるのですが...)、試行錯誤しました。
その結果、動いたコードの簡略版で実装例を紹介します。
コード
#include <pybind11/pybind11.h>
#include <pybind11/stl.h>
void print_arrays(std::vector<int> lst) {
// 配列の長さ
int length = sizeof(lst)/sizeof(lst[0]);
// 配列の各要素を出力する
for (int i=0; i < length-1; i++) {
printf("%d\n", lst[i]);
}
}
// PYBIND11_MODULE()はPythonでimportする際の関数を作成する
PYBIND11_MODULE(example, m) {
m.doc() = "Example pybind11"; // optional module docstring
m.def("print_arrays", &print_arrays, "A function that prints array elements.");
}
実行例
あとは実行するだけです!が、ここで私は躓きました。
失敗したコマンド
上は色んなサイトを調べた結果上手くいったコマンドです。 そして、実際に多くの人が行うように、私も公式ドキュメントに従って、以下のコマンドを実行をしました。
c++ -O3 -Wall -shared -std=c++11 -fPIC `python3 -m pybind11 --includes` example.cpp -o example`python3-config --extension-suffix`
その結果、バーっとエラーが吐かれ(長すぎるため省略します)、最後に
ld: symbol(s) not found for architecture x86_64 clang: error: linker command failed with exit code 1 (use -v to see invocation)
と言われてしまいました。
色々調べた結果、こちらのイシューが参考になりました。
成功したコマンド
そこで、上記のサイトを参考に、以下のコマンドで成功しました。
clang++ -O3 -Wall -shared -std=c++11 -fPIC `python -m pybind11 --includes` -undefined dynamic_lookup example.cpp -o example`python3-config --extension-suffix`
その結果、同じディレクトリにexample.cpython-36m-darwin.soという名前のファイルができたと思います。
詳しくは調べきれていないのですが、多分pyenvの影響かと思うので、使っている人は気をつけてください!
実行結果
ここまで来ればあとは簡単です。
先ほどのコード内でPYBIND_MODULE()という関数を用いて、pythonでインポートする際の関数を生成しました。
あとは、REPLで以下のようにすればいけます。
$ python3 >>> import example >>> example.print_arrays([1, 2, 3, 4, 5]) 1 2 3 4 5 >>>
応用
ここまでやると、本格的にライブラリを作りたくなってきました。
というのも、pybind11の公式ドキュメントにビルドシステムというセクションがあり、自分が作ったライブラリを実際にpipでインストールできるようになるまでが書かれていたからです(Pypiに載せるところまではやらないです)。
ディレクトリ構成
ディレクトリ構成は人それぞれの好みがあると思いますが、今回は公式ドキュメントでも紹介されていたgitのプロジェクトを参考にしました。
pybind11_example/ ├ src/ │ ├ addition.cpp │ ├ subtraction.cpp │ └ main.cpp ├ tests/ │ └ test.py ├ setup.py └ README.md
src/内のコード
src内には任意のファイルを作って大丈夫です!
配列の各要素を足し合わせる関数を格納したファイル
#include <pybind11/stl.h>
int sum_arrays(std::vector<int> lst) {
// 配列の長さ
int length = lst.size();
int sum = 0;
// 配列の各要素を出力する
for (int i=0; i < length; i++) {
sum += lst[i];
}
return sum;
}
配列の各要素の積を返す関数を格納したファイル
#include <pybind11/stl.h>
int product_arrays(std::vector<int> lst) {
// 配列の長さ
int length = lst.size();
int pro = 1;
// 配列の各要素を出力する
for (int i=0; i < length; i++) {
pro *= lst[i];
}
return pro;
}
上記のモジュールを束ねるファイルmain.cpp
#include <pybind11/pybind11.h>
#include "addition.cpp"
#include "product.cpp"
PYBIND11_MODULE(pybind11_example, m) {
m.doc() = "Example pybind11"; // optional module docstring
m.def("sum_arrays", &sum_arrays);
m.def("product_arrays", &product_arrays);
}
ここで、今回はライブラリ名をpybind11_exampleと設定しました。これは後にpipでインストールする際に同じ名前を用いるので、気をつけてください。
setup.py
あとはsetup.pyを記述するだけです。(README.mdやtest/内は省略をします)
これはpybind11の公式ドキュメントにビルドシステムをかなり参考にしました。
基本真似をして、ext_modules=[]とsetup()の中身を書き換えるだけです。
...
ext_modules = [
Extension(
'pybind11_example', // ライブラリ名
['src/main.cpp'], // 参照にするファイル
include_dirs=[
# Path to pybind11 headers
get_pybind_include(),
get_pybind_include(user=True)
],
language='c++'
),
]
...
...
setup(
name='pybind11_example', // ライブラリ名
version=0.1,
author='sff1019',
description='A pybind11 example',
long_description='',
ext_modules=ext_modules,
install_requires=['pybind11>=2.2'],
cmdclass={'build_ext': BuildExt},
zip_safe=False,
)
これで完成です!
実行
pybind11_example11の親ディレクトリに入ります。
$ pip install ./pybind11_example Processing ./pybind11_example ... Successfully installed pybind11-example-0.1
となれば成功です。
あとは好きなところで
import pybind11_example pybind11_example.sum_arrays([1,2,3])
のように実行ができます。 ちなみに、出力は以下のようになります。
6
最後に
最初のpyenvのところだけが突っかかりましたが、思った以上に簡単にC++のコードをpythonにインポートすることができるのだな、と感じました。
参考サイト
Women Techmakers Scholarshipについて

こんにちは、今回はGoogleが主催するWomen Techmakersの奨学金プログラムについて紹介したいと思います!
様々な方がこの体験をブログに綴っているため、他の方のも参考にするといいと思います! 私はどちらかというと、エントリーをするためのエッセイなどに焦点を置いて、経験談をもとに綴ろうと思います!

Women Techmakersとは
Women Techmakersとは、
From 2014 to present, Women Techmakers is continually launching global scalable initiatives and piloting new programs to support and empower women in the industry.
と、ホームページには書かれているのですが、ざっくりいうと、Google主催のテック系で働く女性をサポートするコミュニティみたいな感じです!
多分、この記事を読んでいる方々はテック系を学んでいる女子学生が多いので、こう言ったコミュニティの必要性はすごくわかると思います.
そして、今回紹介しますWomen Techmakers Scholarshipのページは以下になります: www.womentechmakers.com
応募資格
応募資格はざっくり6つほどあります.
To be eligible to apply, applicants must:
- Identify as female
- Currently be enrolled at an accredited university for the 2018-2019 academic year
- All students graduating in 2019 and beyond are eligible to apply
- Be studying computer science, computer engineering, or a closely related technical field
- Demonstrate a strong academic record
- Exemplify leadership and demonstrate passion for increasing the involvement of women in computer science
とまぁ、かなり大雑把な感じがしますよね。
これを翻訳しますと、下記のようなものになります:
下記の要項を満たしたものに応募資格を与える:
- 女性であること
- 2018-2019年現在、認定された大学に所属していること
- 2019年度以降に卒業を控えている全ての学生
- 情報科学、情報工学、またそれらに密接した科学的分野を学んでいる方
- 優れた成績を残していること
- リーダーシップを取り、コンピュータサイエンス系の女性の躍進の推進活動を行なっている
1〜3つ目は女子かつ大学生以上の学生であれば満たされます。
4つ目については「どういうこと?」と感じるかもしれませんが、情報系でなくても参加ができるよ、という趣旨です。実際、参加した方の中には物理系や機械系などと言った方々も参加していました!
そして、5つ目や6つ目あたりが応募を決めるネックになるところかと思います。
まず、優れた成績ってどのレベル?と思われるかもしれせんが、個人的にはとりあえず応募してみることをお勧めします!
大学によって成績のつけ方が違うので!
そして、最後の要項については、結構難しいかと思います。でも、大学の課題やチーム課題、インターンなどを通して語れることが1つでもある方は是非、臆せず応募してみてください!
実際、上記の応募要項の5つ目や6つ目に自信がなくても是非、応募はしてみた方がいいです!
応募書類
応募に必要なものは以下になります:
応募に必要な書類:
- 基本情報
- 履歴書
- 現在と過去の成績表(既に学位を取っていれば)
- 3つの質問に対するショートエッセイ
基本情報
Googleフォームを用いて基本情報を入力します。
履歴書
次に必要なのが、履歴書です。
履歴書では自分の経歴・技術力・表彰されたものや活動などを記しましょう。
Googleはたくさんの履歴書の中から光るものを取り出すので、出来るだけ見やすく、そして自信を持って書いた方がいいです。(もちろん嘘はダメですが...)
履歴書は英語で記入します。私は、myperfectresumeというサイトで作成しました。
成績表
成績表は英語でpdf形式で提出をします。 大学によってはオンラインで取得できなかったり、取り寄せるのに時間がかかったりするようなので、出来るだけ早く取り掛かった方が良さそうです。
エッセイ
そして応募で最も大事なのが、こちらのエッセイです。もちろん、英語です!
しかし、英語だからといって諦めないでください!実際、結構のかたがこのエッセイで諦めているのではないかと思います。
これらの質問は、応募者の情報系に対する情熱や苦労、そして女性の躍進に対する思いやリーダーシップ力などを問いてきます。(少なくとも今年度はそうでした)
応募者は皆色々やってきている方々が多いと思います。しかし、自分に自信を持ってエッセイを書くのがポイントです!「こんなことしかやっていない」、と思っていたことも実は他の人がやっていないことかもしれないので、絶対に自分を過小評価しないでください!
もちろん、誇張しすぎたり、嘘を書いたりするのはダメですが。
エッセイについて
実際にどのようなことを書いたか、次回以降の方の助けとなるように要点を記していきます。
同じ問いが問われるとは思わないので、参考程度に受け止めてください。
1. How do you think computer science, computer engineering and/or a closely related technical field is changing the world? How do you plan to contribute?
よく見る、または議論される問いだと思います。そして、3問の中で最も答えやすい問いなのではないでしょうか。
- コンピュータがどのようなインパクトを社会に施しているのか(昔と比べたり)
- 今までどのような研究・開発をしてきたか. なぜそういった活動をしようと考えたのか
- 将来どのような研究・開発がしたいか. そしてそれがどのような影響をもたらすのか
この問いはどちらかというと、あなたがどういった活動をしてきたのか、そしてどういった活動をして社会に貢献したいのかが焦点になっていると思います。なので、大学の課題でもいいのでどのようなことをしてきたのかを熱意持って語れるといいと思います。
2. Please discuss the structural issues impacting underrepresented groups that you have observed or experienced in computer science, computer engineering, and/or a closely related technical field. What connection and/or effect do you think these have to the industry and/or the wider world?
ここでの underrepresented groups とは「女性」としてコンピュータサイエンスの業界、また似た分野で感じていることを綴ればいいと思います.
そして, 以下のことを書くといいと思います.
- 女性として受けた差別・感じる格差などそれぞれあると思います. 実体験や友人の体験でもいいので紹介する.
- 大学
- インターン先
- イベント
- 誰かと話した時
- etc.
- それがどのように今後, 女性がこの業界で活躍しようとした時に影響を与えるか. また, 単純に他の女性がマイノリティの業界に与えるインパクトがあるのか.
- 実体験をもとにかければ, 尚読み手に印象が残ると思います
3. Please write about an activity that you are currently or recently involved in to address structural issues for underrepresented groups in your field.
Googleでは、リーダーシップが取れる人材を探しています。 そして、女性がもっと活躍できるように活動をしている方々を応援しています。
なので、この問いでは、今まで活動してきた大学の団体において、自分が如何に貢献をしてきたかを紹介しました。
- 自分の貢献度を記す
- 団体内での役割
- 得られた結果(あまり良くなくても、やったということが大事です)
- どのように「女性の躍進」を助けることができたのか
実際、この問いに一番時間をかけた気がします。今まで、自分はこんなにすごい!ということをエッセイなどで記述することがなかったので、非常にやりづらかったです.
しかし、のちに知人に読んでもらった際に、「自分に自信を持ってもっと自慢してもいいと思う」と言われてしまいました... しかし、そのおかげで通過ができたと思います。
皆さんも、自分の活動を過小評価せずに、自信を持って綴ってください!
2次選考
案内
提出後、3週間くらいで2次への案内がメールで届きました。
hangoutで30分ほどの面接をするとの趣旨でした。
ちょうどその時期にアメリカにおり、時差の問題、しかもairbnbに泊まっていたため、
wifiの問題がありました。ただでさえ緊張をしていたのに、余計にうまくいかなかったらどうしようとさらに緊張をしたのを覚えています。
雑談ですが、宿泊していたairbnbのwifiのスピード(https://fast.com/で測った結果です)が最大8.3Mbsしか出なかったので、途中で音声が途切れたりなどしていまた。
皆さんも、万が一に備えて事前にwifi環境はチェックしておいたほうがいいと思います...
ビデオ電話面談
ここでは事前に提出したエッセイに関する質問や、テック系に関して応募者がどのような考えを持っているのか聞いてきます。
英語で答える質問もあるのですが、緊張せずにゆっくり答えれば大丈夫です!
内容などは同期の方が(下に載せてあります)書かれているので、省きます!
合格通知
全ての面接が終わって、1・2週間くらい経つと合格通知がメールできます。 そのメールの1ヶ月後くらいにリトリートプログラムという名で海外(もしくは日本)のGoogleオフィスに行けるので、応募する際はその辺の日程にも気をつけた方がいいかもです。
最後に
自分はエントリーをする際、あまり期待しないで出しました。しかし、自己アピールができていたのがよかったのかな、という風に今は思います。実際、提出する前に他の人に読んでもらうことが一番なのではないかと思います!
以下に他の方が体験を綴ってくれているているので、是非一度読んでみてください! 詳しいプログラムの内容などを書いてくれているので、とても参考になると思います!
他のブログ
日本人
私も、応募をしようとしていた時に過去の先輩方のブログなどを拝見し、より一層いきたいという気持ちが強まりました。
他の方はもっとこのプログラムでどのような活動をするのか紹介しているので、是非読んでみてください!
同期の他の国の方々
少し観点が違うかもしれませんが、似たような体験をもと書いていたりするので、事前に読むとWomen Techmakersのこの奨学生プルグラムの全体像がわかるかもしれません!
また、私よりも丁寧にエッセイのポイントを記してくださったりもしているので、エッセイで困っていたら、是非お勧めします!
全部英語の記事です!
Pytorchの疎行列演算まとめ
疎行列とはほとんどがゼロ要素で埋められているような行列のことを指します. グラフ構造を扱う際に隣接行列やAffinity Matrixが疎な行列となることが多いです. このような行列はすべての要素を保存するのではなく, 非ゼロ要素の座標と値のみを保存する方がメモリ効率がよくなります.
疎行列の保存形式もいくつかあるのですが, PytorchではCOOフォーマットのみをサポートしています. 疎行列のフォーマット(COO, LIL, CSR, CSC)について気になる方は, はむかずさんのscipy.sparseでの疎ベクトルの扱いがとてもわかりやすいです.
Pytorchにおいても疎行列の演算がサポートされていますが, 前述したようにCOOフォーマットのみのサポートであり実装されている演算が限られているなどの制約はありますが, GCNなどのグラフ構造を用いた深層学習の研究が一般化するに連れて今後も開発が進んでいくと考えています.
This API is currently experimental and may change in the near future. とあるようにまだ実験段階の機能なので, As-Isでの機能を紹介する形となりますが, 疎行列のAPIの実装に関してはv1.0.0で大幅に改善されていることもあり, Pytorchのバージョンはv1.0.0を利用して検証を行いました.
疎行列の演算に関する公式ドキュメントがほとんどない状態なので少しでも理解の助けになれば嬉しいです.
疎行列の初期化方法
一般的なCOO形式の疎行列の初期化方法と同じく, インデックスの座標と値をペアになるように渡すことで初期化ができます.
>>> i = torch.LongTensor([[0, 1, 1], [2, 0, 2]]) >>> v = torch.FloatTensor([3, 4, 5]) >>> sm = torch.sparse.FloatTensor(i, v, torch.Size([2,3])).to_dense() 0 0 3 4 0 5 [torch.FloatTensor of size 2x3]
最近になって密行列を疎行列に変換するメソッドが実装されました.
下記のように密行列をto_sparse() メソッドで疎行列に変換できます.
>>> sm = torch.randn(2, 3).to_sparse() tensor(indices=tensor([[0, 0, 0, 1, 1, 1], [0, 1, 2, 0, 1, 2]]), values=tensor([ 1.5901, 0.0183, -0.6146, 1.8061, -0.0112, 0.6302]), size=(2, 3), nnz=6, layout=torch.sparse_coo, requires_grad=True)
また, 疎行列の諸情報を取得したい場合は以下のメソッドが利用できます.
インデックスの取得
>>> sm._indices() tensor([[ 0, 1, 1], [ 2, 0, 2]])
値の取得
>>> sm._values() tensor([ 3., 4., 5.])
非ゼロ要素数の取得
>>> sm._nnz()
3
転置行列の取得
>>> sm.t() torch.sparse.FloatTensor of size (3,2) with indices: tensor([[ 2, 0, 2], [ 0, 1, 1]]) and values: tensor([ 3., 4., 5.])
疎行列の演算
Pytorchでは基本的な疎行列の演算が実装されています.
torch.sparse.mm(mat1, mat2) → Tensor
引数が mat1 はsparse.Tensorで, mat2がTensorである必要があるということに注意してください.
疎行列と密行列の行列積の計算はv1.0.0以前からtorch.spmm(mat1, mat2)を用いることで計算可能でしたが, 疎行列の勾配を求めることができませんでした.
例えば下記のコードはエラーになります.
>>> a = torch.sparse.FloatTensor(i, v, torch.Size([2,3])).requires_grad_(True) >>> b = torch.rand(3, 2, requires_grad=True) >>> c = torch.spmm(a, b) >>> y = c.sum() >>> y.backward() RuntimeError: calculating the gradient of a sparse Tensor argument to mm is not supported.
これに対して, torch.sparse.mm(mat1, mat2)メソッドを使うことによって, 疎行列に対しても誤差逆伝搬を適用することができるようになっています.
>>> c = torch.sparse.mm(a, b) >>> y = c.sum() >>> y.backward() >>> a.grad tensor(indices=tensor([[0, 1, 1], [2, 0, 2]]), values=tensor([1., 1., 1.]), size=(2, 3), nnz=3, layout=torch.sparse_coo)
torch.sparse.addmm(mat, mat1, mat2, alpha=1, beta=1) → Tensor
下式のように和と行列積を同時に計算します.
引数が mat, mat2 はTensorで, mat2がsparse.Tensorである必要があるということに注意してください.
$\text { out } = \beta \text { mat } + \alpha \left( \operatorname { mat } 1 _ { i } @ \operatorname { mat } 2 _ { i } \right)$
>>> a = torch.sparse.FloatTensor(i, v, torch.Size([2,3])).requires_grad_(True) >>> b = torch.randn(3, 2, requires_grad=True) >>> c = torch.randn(2, 2, requires_grad=True) >>> d = torch.sparse.addmm(c, a, b) >>> d.grad_fn <SparseAddmmBackward object at 0x110000000> >>> y = d.sum() >>> y.backward() >>> a.grad tensor(indices=tensor([[0, 1, 1], [2, 0, 2]]), values=tensor([2.6244, 1.9874, 2.6244]), size=(2, 3), nnz=3, layout=torch.sparse_coo)
torch.sparse.sum(input, dim=None, dtype=None) → Tensor
疎行列の要素の和を計算します. このメソッドに関しても疎行列に関しての誤差逆伝搬が可能になっています.
>>> a = torch.sparse.FloatTensor(i, v, torch.Size([2,3])).requires_grad_(True) >>> y = torch.sparse.sum(a) >>> y.grad_fn <SumBackward0 object at 0x1016c7208> >>> y.backward() >>> a.grad tensor(indices=tensor([[0, 1, 1], [2, 0, 2]]), values=tensor([1., 1., 1.]), size=(2, 3), nnz=3, layout=torch.sparse_coo)
まとめ
公式ドキュメントの焼き直しのようになってしまいましたが, Pytorchでの疎行列の演算の方法を簡単にまとめてみました. 追記の必要, 間違い等あれば気軽にコメントください.
From Shun